



Handling Connected Domains with the “Right Tool for the Job”
Sarah Mei recently wrote a great blog post describing the problems she and her colleagues ran into when managing highly connected data using document databases.
Document databases (like other aggregate stores) do a good job at storing a single representation of an aggregate entity, but they struggle to handle use cases that require multiple, different views of the domain. Handling connections between documents tends to be an afterthought that isn’t covered well by the aggregate data model.
Real-World Use Cases
Sarah described how she worked on a TV show application at Pivotal and discussed the modeling and data management implications that surfaced when the application’s use case evolved.
The same applied when working on the Diaspora project which started out as a Ruby on Rails application using MongoDB.
For both projects, these requirements caused difficulties with the chosen data model and database which triggered the move to PostgreSQL. A relational database was chosen as it allowed some of the fidelity in the model to return.
Unfortunately this comes at the cost of dealing with queries with a high number of JOINS which can cause performance issues.
Fortunately, there is a data model that embraces rich connections between your domain entities: Graph databases.
Live Graph Data Models of Diaspora and the TV Show
To show how a graph database would handle these use cases, we created two live graph data models of both a social network like Diaspora and a TV show graph.
To this end, we set up a small example data set and then represent the use-cases she mentioned as a set of graph search queries with the Cypher graph query language. These GraphGists allow for easy modeling discussions, a live exploration of the dataset, and provide a good starting point for your own (forked) variant of the domain model.
Example Graph Data Model – TV Shows
To quickly develop the models, we use the typical patterns that we’re looking for in a graph when answering the use cases described. We call it whiteboard-friendlyness 🙂
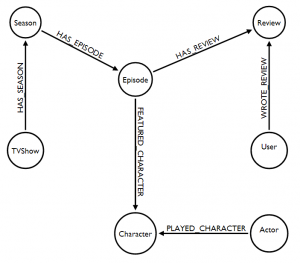
Here are some example patterns we might want to model for:
Shows, seasons and episodes:
(:TVShow)-[:HAS_SEASON]->(:Season)-[:HAS_EPISODE]->(:Episode)
Characters played by actors featured in a episode:
(:Episode)-[:FEATURED_CHARACTER]->(:Character), (:Character)<-[:PLAYED_CHARACTER ]- (:Actor)
Users writing reviews for individual episodes:
(:User)-[:WROTE_REVIEW]->(:Review)<-[:HAS_REVIEW]-(:Episode)
Using these basic patterns we can quickly create sample data for the domain and also develop the queries used to solve the use cases. For example:
Listing all the episodes (filmography) of an actor across episodes and shows:
MATCH (actor:Actor)-[:PLAYED_CHARACTER ]->(character), (character) <-[:FEATURED_CHARACTER]- (episode), (episode)-[*]->(show:TVShow) WHERE actor.name = "Josh Radnor" RETURN show.name, episode.name, character.name
If you want to learn more, please check it out in more detail in the live graph model.
Example Graph Model – Social Network

Again, a few examples of patterns we’ll be looking for:
Users, friends and posts:
(:User)-[:FRIEND]->(:User)-[:POSTED]->(:Post)
Posts, comments and commenters:
(:User)-[:POSTED]->(:Post)<-[:COMMENTED]-(:User)
Users like posts:
(:User)-[:LIKED]->(:Post)
Now for our Cypher queries. Find the posts made by Rachel’s friends:
MATCH (u:User)-[:FRIEND]-(f)-[:POSTED]->(post) WHERE u.name = "Rachel Green" RETURN f.name AS friend, post.text as content
List people who commented on posts by Rachel’s friends:
MATCH (u:User)-[:FRIEND]-(f)-[:POSTED]->(post)<-[:LIKED]-(liker) WHERE u.name = "Rachel Green" RETURN f.name AS friend, post.text as content, COLLECT (liker.name) as liked_by
And you can see the rest in the live graph model.
Graph Databases as a Niche Technology?
As you can see, it is incredibly easy to model these use cases with a graph database. So why weren’t they considered? To quote from the article:
But what are the alternatives? Some folks say graph databases are more natural, but I’m not going to cover those here, since graph databases are too niche to be put into production.
This is an interesting observation, as Neo4j is the most widely used graph database and has been running in production setups for more than 10 years now.
Neo Technology has hundreds of customers (and many of them are household-name enterprises), and there are even more community users that deploy Neo4j for their production applications. The industries of these use cases span everything from network management, gaming, social, finance, job search to logistics and dating sites.
We can understand why some people may have felt that graph databases were a niche technology in 2010 when Diaspora got started – we actually backed Diaspora on Kickstarter and offered our help at the time – but now the landscape has changed and graph databases are an uncontroversial choice.
Judge for Yourself
If you work in a domain with richly connected data, we encourage you to try to model it as a graph and manage it with a graph database. For some more insights of how this works, feel free to check out the freely available book Graph Databases by O’Reilly.
Also, the offer to support Diaspora still stands! We’re happy to help, so please reach out to us if you’re interested. You can also follow the discussion with Sarah on Twitter. Feel free to jump in!
Cheers,
Michael Hunger
with help from Kenny Bastani, Mark Needham and Peter Neubauer.
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your mission-critical application today.





