


What is MusicBrainz?

|
| Paul Tremberth |
Quoting
Wikipedia
,
MusicBrainz
is an “open content music database [that] was founded in response to the restrictions placed on the CDDB.(…) MusicBrainz captures information about artists, their recorded works, and the relationships between them.”
Anyone can browse the database at
https://musicbrainz.org/
. If you create an account with them you can contribute new data or fix existing records details, track lengths, send in cover art scans of your favorite albums etc. Edits are peer reviewed, and any member can vote up or down. There are a lot of similarities with Wikipedia.

|
| https://en.wikipedia.org/wiki/MusicBrainz |
With this first post, we want to show you how to import the Musicbrainz data into Neo4j for some further analysis with
Cypher
in the second post. See below for what we will end up with:

|
| American artists signed on British record labels |
START usa=node:mb_fulltext(name=”United States”),
gb=node:mb_fulltext(name=”United Kingdom”)
MATCH (usa:Country), (gb:Country),
(a:Artist)-[:FROM_AREA]-(usa),
(a:Artist)-[:RECORDING_CONTRACT]-(l:Label),
(l)-[:FROM_AREA]-(gb)
RETURN a,l,usa,gb
gb=node:mb_fulltext(name=”United Kingdom”)
MATCH (usa:Country), (gb:Country),
(a:Artist)-[:FROM_AREA]-(usa),
(a:Artist)-[:RECORDING_CONTRACT]-(l:Label),
(l)-[:FROM_AREA]-(gb)
RETURN a,l,usa,gb
MusicBrainz data
MusicBrainz currently has
around 1000 active users
,
nearly 800,000 artists, 75,000 record labels, around 1,200,000 releases, more than 12,000,000 tracks, and short under 2,000,000 URLs for these entities (Wikipedia pages, official homepages, YouTube channels etc.)
Daily fixes by the community makes their data probably the freshest and most accurate on the web.
That’s a lot of interlinked data! Which makes it a perfect candidate for Neo4j.
All entities (artists, labels, releases, etc.) are identified by their
MusicBrainz Identifier
(MBID
. It’s probably the closest to an universal UUID for the music recording industry.
To find the MBID of your favourite band, do a search from the homepage’s search bar on the top, click on the artist you want (there can be many homonyms) and in the address bar of your browser, the MBID is the last part of the URL. For example, this is the URL for Maxïmo Park’s page on MusicBrainz:
The MBID has become the de-facto reference point for music data, with e.g. Last.fm and many others using it
The License of the Musicbrainz data
When it comes to public data sources, the question of their license is always one of the first things to look at. In the Musicbrainz case, these are the two interpretations out there.
Core data
The core data, as noted above, is licensed under the CC0, which is effectively placing the data into the Public Domain. This means that anyone can download and use the core data in any way they see fit. No restrictions, no worries!
From Wikipedia,
Since 2003,[10] MusicBrainz’s core data (artists, recordings, releases, and so on) are in the public domain, and additional content, including moderation data (essentially everyoriginal content contributed by users and its elaborations), is placed under the Creative Commons CC-BY-NC-SA-2.0 license.[
Relational model
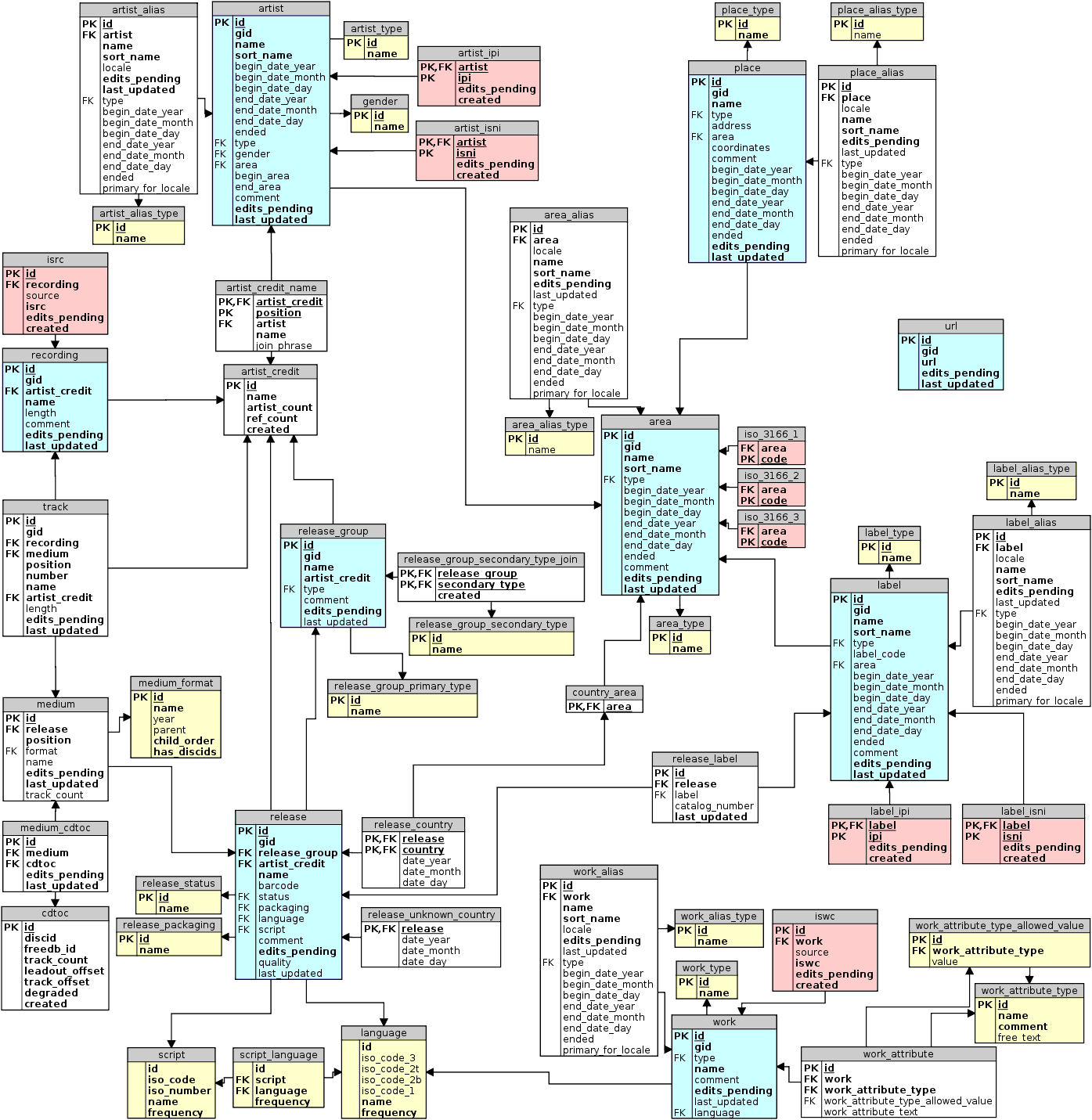
The MusicBrainz server is written in Perl with a PostgreSQL backend. It’s actually open-source. and you can have a look at the table schema on github:
https://github.com/metabrainz/musicbrainz-server/blob/master/admin/sql/CreateTables.sql
Here’s how the different tables are linked in MusicBrainz’ relational model:


As you can see the tables are deeply normalized and it’s a bit intimidating when you start diving into it. (the so-called NGS, Next Generation Schema,
https://wiki.musicbrainz.org/Next_Generation_Schema
)
What would MusicBrainz data look like in a graph?
The entities in our graph will be assigned Neo4j Labels that are roughly corresponding to the SQL table names (the names in the bubbles). Below a simplified view of how MusicBrainz entities are linked in the graph model of Neo4j:

|
| Neo4j Musicbrainz Schema |
What’s with the “Artist Credit” entity?
Well, it’s for when more than one artist worked or performed on a track or a record.
For example, “Telephone” by Lady Gaga also features Beyoncé (
https://musicbrainz.org/recording/4daf26b7-7cf3-4752-bebc-9bb23a4648e1
) so the artist credit for that recording references two artists, Lady Gaga (MBID 650e7db6-b795-4eb5-a702-5ea2fc46c848) and Beyoncé (MBID 859d0860-d480-4efd-970c-c05d5f1776b8). But the track credit is “Lady Gaga feat. Beyoncé”. You can find more details here:
https://musicbrainz.org/doc/Artist_Credit
How to import MusicBrainz data into Neo4j?
“That all nice and pretty but how do I get this wonderful dataset into Neo4j?”
The SQL2GRAPH tool
sql2graph
was inspired by Max De Marzi blog posts on using batch-import: part 1 (https://maxdemarzi.com/2012/02/28/batch-importer-part-1/) and part 2 (https://maxdemarzi.com/2012/02/28/batch-importer-part-2/). It is a set of Python scripts that ease during mirgation from relational databases to Neo4j, the Musicbrainz migration being one example,
see here
for detailed instructions.
Step 1 – get a local copy of the database
You can have you own PostgreSQL mirror of the MusicBrainz database using a nifty Python project called “mbslave” by Lukáš Lalinský (
https://bitbucket.org/lalinsky/mbslave
) and feed it with a MusicBrainz database dump (get this dump following the instructions from
https://wiki.musicbrainz.org/MusicBrainz_Database/Download
). The core data dump
mbdump.tar.bz2
is in the public domain and is 1.5GB. Please use the mirror that is closest to you (EU or US). You should be good to go with that.
See
https://musicbrainz.org/doc/MusicBrainz_Database/Download
for other ways to get the data (virtual machine, MySQL mirror).
Step 2 – Export data to CSV/TSV with sql2graph
For this amount of data (around 30M core entities and lots of relationships between them), there’s a tool that we recommend: Michael Hunger’s
batch-import project
(right now take the “20” branch for Neo4j 2.0 support).
It’s a tool that takes TAB-separated values files as input and populates a Neo4j datastore. The format is rather straightforward, and usually requires as little as two files: first one with nodes and their properties, and the second one for the relationships between those nodes.
You can build these files in a number of ways but I wrote a Python module to help you with that: sql2graph (
https://github.com/redapple/sql2graph
)
How sql2graph operates
sql2graph needs a little help too from you in that it takes as input a (Python) representation of the schema mapping from SQL tables to graph nodes, properties and relationships. (The Python classes used in sql2graph schema mapping are heavily borrowed from mbslave code to export MusicBrainz to Solr.)
For each core entity we would like as nodes in our graph, we convert the corresponding SQL table schema to an Entity and it’s Properties.
For example, the “artist” table (
https://github.com/metabrainz/musicbrainz-server/blob/master/admin/sql/CreateTables.sql#L95
) is mapped to:
Entity(‘artist’,
[
IntegerProperty(‘pk’, Column(‘id’)),
Property(‘mbid’, Column(‘gid’)),
Property(‘disambiguation’, Column(‘comment’)),
Property(‘name’, Column(‘name’)),
],
All Entity() instances have:
-
a name , here “artist”, that will become an :Artist label for the nodes.
-
a list of Property() instances, that also have a name, that will become properties of the node
-
a mandatory primary key property called “pk” that is use by sql2graph to resolve links between entities when creating relationships; this is usually the column name “id” in SQL tables (this “pk” property is not really useful in the final graph)
Each Property() can either reference an SQL column in the same table or in a linked table (via a ForeignColumn() instance as 2nd parameter)
What about relationships?
Entities can have relationships with other entities (that’s the whole point of wanting to put them in a graph, right?). You define those after the Properties list for your nodes, as a list of Relation() instances.
Let’s continue with the “artist” core entity example,
Entity(‘artist’,
[
IntegerProperty(‘pk’, Column(‘id’)),
Property(‘mbid’, Column(‘gid’)),
Property(‘disambiguation’, Column(‘comment’)),
Property(‘name’, Column(‘name’, ForeignColumn(‘artist_name’, ‘name’))),
],
[
Relation(
‘FROM_AREA’,
start=Reference(‘artist’, Column(‘id’)),
end=Reference(‘area’, Column(‘area’)),
properties=[]
),
Relation(
‘BEGAN_IN_AREA’,
start=Reference(‘artist’, Column(‘id’)),
end=Reference(‘area’, Column(‘begin_area’)),
properties=[]
),
Relation(
‘ENDED_IN_AREA’,
start=Reference(‘artist’, Column(‘id’)),
end=Reference(‘area’, Column(‘end_area’)),
properties=[]
),
],
),
We just defined 3 relationship types:
-
‘FROM’: represents the relationship between the “artist” table and the “area” table, representing where an artist is from (was born or built his career in)
-
‘BEGAN_IN’ and ‘ENDED_IN’ also represent a link between the “artist” and “area” tables but they represent the place of birth and place of death of artist (or band sometimes)
All Relationships must have a “start entity” and an “end entity”
, using the Reference() class, which is very similar to the Property() class.
Finally, relationships can also have properties of their own. So you can add Property() objects as fourth parameter to Relation. Example with the “release_label” table that links a release to the record label that released it (obviously ;), and that table can contain a catalog number info. This is translated into:
Entity(‘release_label’,
[],
[
Relation(
‘RELEASED_ON’,
start=Reference(‘release’, Column(‘release’)),
end=Reference(‘label’, Column(‘label’)),
properties=[
Property(‘catalog_number’, Column(‘catalog_number’)),
]
),
]
),
For the “release_label” table, we do not need to create nodes in Neo4j, we’re only interested in the relationship between the two entities “release” and “label”, so the Properties parameters is left to an empty Python list, [].
Exporting nodes and relationships using SQL queries
Once you have this schema mapping defined, you can run sql2graph and it will output a nice SQL script that you give to psql which can export directly to TSV.
sql2graph was inspired by Max De Marzi blog posts on using batch-import:
part 1 (
part 1 (
Batch Importer – Part 1) and part 2 (
Batch Importer – Part 2)
It operates in 3 steps:
-
first, it creates a temporary table (in the RDBMS itself) mapping entity primary keys values to node IDs in Neo4j. This SQL table has 3 columns: “entity”, “pk” and “node_id”
-
then, it dumps nodes data for all tables for which you defined node properties in TSV format (PostgreSQL can do that, see
Batch Importer – Part 2
) -
finally, it exports relationships as TSV, using the Relation() and Property() instances you defined in the mapping above, and resolving node IDs using the temporary table
|
SQL table “artist”:
SQL table “label”:
|
Temporary mapping table:
|
“Oh, man, but MusicBrainz has so many tables… Do I really have to define this schema translation thing on my own? and in Python??”
In fact we did the work for you. Either tweak the mapping to add or remove a few properties or entities, and run sql2graph… or simply grab the SQL export script and feed it to psql.
$ git clone git@github.com:redapple/sql2graph.git
$ cd sql2graph
$ ./musicbrainz2neo4j-export.py > musicbrainz2neo4j.sql
A pre-generated SQL file is available at sql2graph/examples/musicbrainz/musicbrainz2neo4j.sql
batch-import supports automatic indexing if your CSV header’s columns contain a type and index name, for example “name:string:mb” if the “name” field in nodes is a string that you want to index in an index called “mb”.
$ cd /path/to/mbslave
$ cat /path/to/musicbrainz2neo4j.sql | ./mbslave-psql.py
The generated MusicBrainz SQL export script above assumes 2 indexes: “mb_fulltext” as a fulltext index and “mb_exact” as an exact index. Make sure your batch.properties file declares those 2 indexes (see below “Import using batch-import”):
-
“mbid” columns will be indexed in the “mb_exact” index and “type” columns will become labels on nodes
-
“name” will be indexed in the “mb_fulltext” index
By default the SQL export script tells psql to output two files, into the /tmp directory, one for nodes and one for relationships: musicbrainz__full__nodes.csv and musicbrainz__full__rels.csv.
Step 3 – Import using the Neo4j batch-import
Running batch import with those two files should give you something like: (on Paul’s small machine it takes roughly 1h and 30 minutes, on a better MacBookPro about 20 minutes). Be sure to adjust your neo4j configuration to something that gives the importer good resources. Peters
batch.properties
file looks something like
batch_import.keep_db=true
batch_import.mapdb_cache.disable=true
batch_import.node_index.mb_fulltext=fulltext
batch_import.node_index.mb_exact=exact
batch_import.csv.quotes=false
cache_type=none
use_memory_mapped_buffers=true
neostore.nodestore.db.mapped_memory=300M
neostore.relationshipstore.db.mapped_memory=3G
neostore.propertystore.db.mapped_memory=500M
neostore.propertystore.db.strings.mapped_memory=500M
neostore.propertystore.db.arrays.mapped_memory=0M
neostore.propertystore.db.index.keys.mapped_memory=15M
neostore.propertystore.db.index.mapped_memory=15M
With that, we can import the files (using UTF-8 encoding) with
cd /path/to/jexp/batch-import
MAVEN_OPTS=”-server -Xmx10G -Dfile.encoding=UTF-8″ mvn exec:java -Dfile.encoding=UTF-8 -Dexec.mainClass=”org.neo4j.batchimport.Importer” -Dexec.args=”batch.properties musicbrainz.db /tmp/musicbrainz__nodes__full.csv /tmp/musicbrainz__rels__full.csv”
And get output like
Usage java -jar batchimport.jar data/dir nodes.csv relationships.csv [node_index node-index-name fulltext|exact nodes_index.csv rel_index rel-index-name fulltext|exact rels_index.csv ….]
Using Existing Configuration File
Importing musicbrainz__nodes__full.csv…
………………………………………………………………………………………. 512172 ms for 10000000
………………………………………………………………………………………. 608539 ms for 10000000
………………………………………………………………………………………. 588464 ms for 10000000
…………………………………………….
Importing 35294004 Nodes took 2057 seconds
Importing musicbrainz__rels__full.csv…
………………………………………………………………………………………. 438932 ms for 10000000
………………………………………………………………………………………. 338665 ms for 10000000
………………………………………………………………………………………. 194668 ms for 10000000
………………………………………………………………………………………. 421573 ms for 10000000
………………………………………………………………………………………. 535700 ms for 10000000
………………………………………………………………………………………. 529039 ms for 10000000
………………………………………………………………………………………. 634684 ms for 10000000
…………………..
Importing 72373185 Relationships took 3249 seconds
Total import time: 5595 seconds
paul@wheezy:/path/to/neo4j/musicbrainz$
Now, let’s point our Neo4j server to our newly created Musicbrainz database in its
neo4j-server.properties
and look at some sample query: Voila!

|
| British artists signed on American record labels |
The Cypher query for this result:
START usa=node:mb_fulltext(name=”United States”),
gb=node:mb_fulltext(name=”United Kingdom”)
MATCH (gb:Country), (gb:Country),
(a:Artist)-[:FROM_AREA]-(gb),
(a:Artist)-[:RECORDING_CONTRACT]-(l:Label),
(l)-[:FROM_AREA]-(usa)
RETURN a,l,usa,gb
In the next post, we will explore some interesting queries on this data, stay tuned!
Thanks a lot to Michael Hunger, Peter Neubauer, Max DeMarzi and the fantastic Neo4j community for all the help and inspiration for this blog!
/paul tremberth, @ skywy






{kind=link}